

哈希游戏平台梁文锋又掀桌?在省钱这件事上DeepSeek给V4模型铺垫好了
哈希游戏作为一种新兴的区块链应用,它巧妙地结合了加密技术与娱乐,为玩家提供了全新的体验。万达哈希平台凭借其独特的彩票玩法和创新的哈希算法,公平公正-方便快捷!万达哈希,哈希游戏平台,哈希娱乐,哈希游戏元旦前,DeepSeek发了新架构mHC,对深度学习的地基Resnet进行了优化,上周又把那篇R1的论文扩写了64页,详细公开了训练路径,这次发的新论文还准备修一修Transformer,顺便在硬件上再省一笔。

这篇论文是DeepSeek和北京大学合作完成的,作者栏依然有梁文锋本人署名。
2017年,谷歌一篇名为《Attention Is All You Need》的论文正式将Transformer这种深度学习架构呈现在了大家眼前,证明了完全基于自注意力机制(Self-Attention)的模型在机器翻译任务上优于当时的循环神经网络(RNN)和卷积神经网络(CNN)。
这篇论文是深度学习领域,尤其是自然语言处理(NLP)的重要转折点,也被看作是现代人工智能的奠基性论文,甚至成为了21世纪NLP领域被引用次数最多论文之一。今天,我们能看到的绝大多数大语言模型也都是以Transformer作为核心架构的。
然而,DeepSeek他们发现Transformer并不是神,它有一个非常反人类的缺陷。它没有真正的记忆模块,它的记忆全是靠“算”出来的 。
在标准的 Transformer 架构中,无论一句话多么常见、结构多么固定,模型都会在每一层里反复计算 token 之间的关系。其实在人的语言和思维里,“固定搭配”这件事是很常见的,比如“中国四大…”后面就得接“发明”,英语里by the 后面基本接的就是way。
可是transformer不是这么思考问题的,四大发明、by the way这种在人类看来固定搭配的词组,在模型内部,仍然被拆成多个token(词元),即使这种组合关系在训练语料里已经被见过成千上万次,但模型还是每次都重新组合和理解。
再复杂一点来说,比如你问大模型一个很简单的问题:东汉末年的张仲景是谁?在现在的Transformer架构下,模型的神经网络大脑就会开始动用几百亿参数,再经过几十层的向量计算,最后说:“是医圣”。
DeepSeek团队就觉得,这太浪费算力了,其实“张仲景是医圣”这件事背下来就行。因为只要涉及计算,那肯定就是非常费脑子的事,对于AI来说,费的就是显存。换句话说就是,太费钱了!
这次的论文提出的记忆模块Engram解决的就是这个事,大模型并不是每一步都需要“算”。
如今,为了更好地节省资源,MoE成为大模型主流架构,但MoE最核心、最本质的架构组件仍然是Transformer,缺少“查表”的能力。
Engram很像是给大模型装了一个外接的大字典,他们把“医圣张仲景”“四大发明”这些固定的知识点,通过 N-gram 机制做成了一个巨大的索引表。以后遇到新问题,能查表的查表,需要算的再算,两件事分开干。
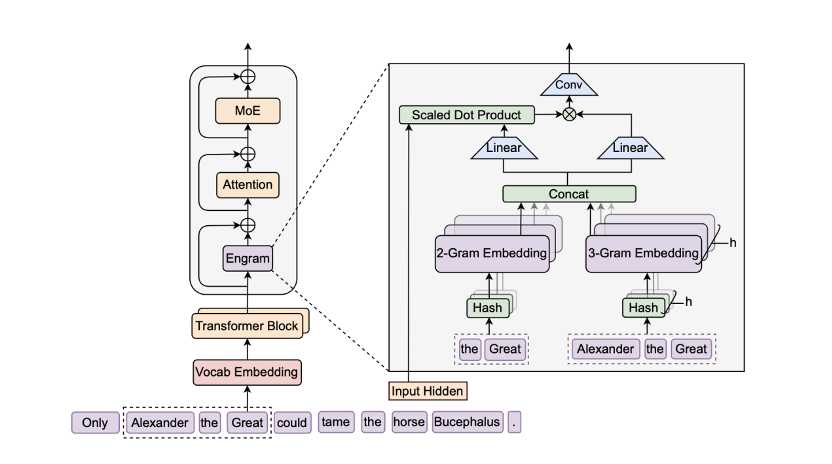
DeepSeek 设计了一个精妙的“门控机制”(Context-aware Gating)。模型会自己判断,遇到“四大发明”“勾股定理”这种死知识,Engram 模块直接查表给答案,省时省力。
遇到复杂的逻辑推理或阅读理解,Engram就退后,让Transformer的核心计算层(MoE)去深度思考。
结果就是不仅省力,还变强了。论文中的实验数据显示,这种“查表+推理”的混合模式,比纯粹靠堆参数的 MoE 模型更强。Engram在知识问答、代码、数学和逻辑推理的能力都有提升。
Engram 的核心逻辑是构建一个巨大的、外挂式的 N-gram 嵌入表,并通过精细的机制将其无缝融合到 Transformer 主干中。
首先是词表压缩,标准的分词器往往会将语义相同但写法微异的词分配不同的 ID,比如 “Apple”和“apple”,这就导致N-gram空间极其稀疏且存在冗余。Engram就把 tokenizer的id做了压缩,把同意词合并,论文里提到128k词表下能压缩近23%。这就显著提高了语义密度,使得N-gram 查表更高效。
Engram还采用了多头哈希的方法。因为直接存储所有可能的 N-gram 组合是不现实的,那么为了解决哈希冲突,Engram 对每个 N-gram 阶数n使用K个不同的哈希头。每个头使用独立的哈希函数将 N-gram 映射到嵌入表的一个索引位置。
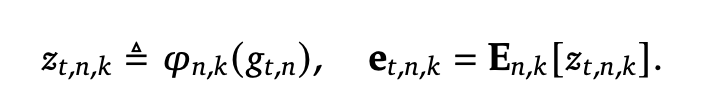
由于查表得到的向量e是静态的,且可能包含哈希冲突带来的噪声。如果直接加到模型里,会干扰上下文。所以Engram还设计了一套门控机制来“过滤”和“融合”这些信息。
传统大模型有一个硬约束,参数要参与计算,得在GPU显存里。过去几年,大模型的发展默认接受了一条前提:参数越多,模型越大越好,显存就必须越大。
无论是H100还是 H200,最贵的往往是那块容量有限且速度极快的HBM。所以,为了塞下几千亿参数的大模型,科技公司不得不买成千上万张显卡。
同时受地缘政治与出口管制影响,中国市场能够稳定获得的HBM资源愈发有限,价格也水涨船高。其实英伟达H20等对中国版的GPU,最关键的限制基本都落在HBM上,算力反而是次要被约束的。
HBM目前产能基本和SK海力士、三星和美光锁死,已经是供不应求,同时价格也非常昂贵,平均是普通内存价格的7倍左右。
在这样的背景下,把模型全塞进显存这条路线,就越来越不可持续了。DeepSeek这篇论文证明了,其实不需要把所有参数都塞进昂贵的显存里。
具体是怎么做到的呢?首先,Engram 的记忆访问是可预测的,它不像 MoE 那样,必须算完这一层才知道下一层要去哪,数据必须都在 GPU 上待命。Engram的索引只由输入token决定,在推理开始前就可以计算出来。
第二,大部分参数其实是“冷的”。自然语言天然遵循 Zipf 分布,极少数短语被反复使用,而绝大多数组合几乎从不出现。Engram正好利用了这一点,将高频记忆放在显存或主内存,低频记忆放在更便宜、更大的存储中。
在论文中,DeepSeek 甚至把一个1000亿参数规模的Engram记忆表,完整放在CPU里,仅在需要时预取,结果整个推理速度的损耗甚至低于3%。
在算力和显存都越来越贵、越来越稀缺的当下,Engram 给行业提供了一条比较现实的路径,不是所有性能提升都必须用更贵的硬件来换。
至此,稀疏化模型也进入了计算+记忆的时代,如果即将推出的DeepSeek-V4真的把此前发布的mHC和这次发布的Engram落地,那将又是一次架构范式的跃迁,让我们拭目以待吧!返回搜狐,查看更多