

哈希游戏平台深入了解哈希算法
哈希游戏作为一种新兴的区块链应用,它巧妙地结合了加密技术与娱乐,为玩家提供了全新的体验。万达哈希平台凭借其独特的彩票玩法和创新的哈希算法,公平公正-方便快捷!万达哈希,哈希游戏平台,哈希娱乐,哈希游戏什么是哈希算法?相信大部分人都不太了解,今天小编为了让大家更加了解哈希算法,给大家总结了以下内容,一起往下看吧。
HashTable--哈希表,是一种典型的 key--value 形式的数据结构,构建这种数据结构的目的,是为了使用户通过 key 值快速定位到我的 value ,从而进行相应的增删查改的工作。当数据量较小时,简单遍历也能达到目的,但面对大量数据处理时,造成时间和空间上的消耗,不是一般人可以承担的起的。
我们的目的是在一堆数据中查找(这里以×××为例),为了节省空间,我们不可能列出一个有所有数据范围那么大的数组,因此这里我们需要建立一种映射关系HashFunc,把我的所有数据通过映射放到这段空间当中,因此哈希表也叫作散列表。
直接定址法是最简单的方法,取出关键字之后,直接或通过某种线性变换,作为我的散列地址。例如:Hash(key) = key*m+n;其中m、n为常数。
除留余数法是让我的关键码 key 通过对我的数组长度取模,得到的余数作为当前关键字的哈希地址。
除了以上的两种方法,还有平方取中法、折叠法、随机数法、平方分析法等,虽然方法不同,但目的都是一样的,为了得到每个关键字 key 的地址码,这里不再赘述。
经过 HashFunc 函数处理之后,得到了每个关键字的哈希地址,正如上面提到的,很容易出现两个关键码的哈希地址相同或者哈希地址已经被其他关键字占用的情况,这种情况我们叫做哈希冲突,或者哈希碰撞。这是在散列表中不可避免的。
载荷因子表示的是填入表中的数据占表总长度的比例。当我们在哈希表中查找一个对象时,平均查找长度是载荷因子 α 的函数。散列表的底层是一个vector,当载荷因子超过一定量的时候,我们需要对vector进行resize扩容,来减小哈希表的插入及查找压力。
为了解决哈希冲突,这里有两种方法闭散列法开放定址法和拉链法哈希桶

需要指出的一点,开放地址法构造的HashTable,对载荷因子的要求极其重要。应严格限制载荷因子在0.7~0.8以下,超过0.8,查表时的不命中率会成指数上升。
上面我们提到了两种HashFunc,针对这两种方法得到的哈希地址之后,我们可以做如下处理。当得到的地址码已经被占用,则我当前 key 的地址向后推移即可。这种方法叫做线性探测。
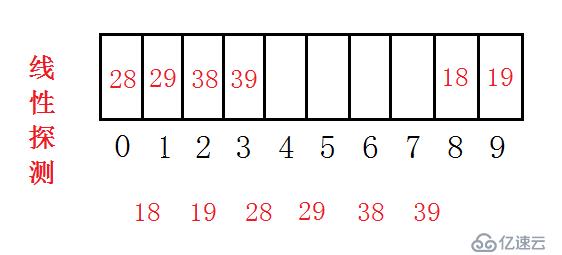
另外还有一种方法,二次探测法。解决思想是当我的哈希地址冲突后,每次不再是加1,而是每次加1^2,2^2,3^2...直到找到空的地址,这种方法很明显可以将各个数据分开,但会引入一个问题,会导致二次探测了多次,依然没有找到空闲的位置。这里用同一组例子来说明。
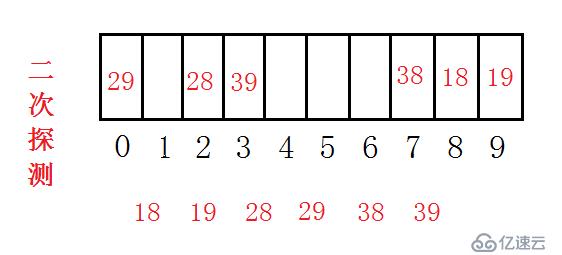
除此之外,为了减少哈希冲突,前人总结出了一组素数表,经过数学计算表明,使用苏鼠标对其做哈希表的容量,可以有效的降低哈希冲突。
这里首先给出哈希表中每个元素结点的类,同时给出 HashTable 的框架除了key、value之外,多增加了一个状态位,当下面用到的时候,会具体给出原因。
这里要注意的一点,因为对于key_value类型的数据结构而言,关键字 key 是唯一 的,因此,当在调整的时候发现了和待插入 key 一样的值,直接返回 false 结束插入函数。
对于哈希表的删除,这里采用的是伪删除法。即找到该 key 之后,将该点的状态改为DELETE即可,因为我们在对 vector 进行扩容的时候,是通过resize实现的,不论是增加元素还是删除,resize出来的空间不需要去释放,这里可以减少内存的多次开辟与释放,提高效率。
另外,假设我们可以将这段空间的内容清空,会带来的问题就是,之前我们插入的时候,所有经过该结点调整过的key都需要重新移动,否则这个元素我们再也找不到。这就是我们这里引入三个状态的原因。
当找到该结点的位置之后,如果 key 值不是我们想要的 key 值,就需要继续向后找,只有当结点的状态位EMPTY时,查找才会停止,当然如果找到的EMPTY还是没有找到我们想要的 key 值,那么该关键字一定不在当前的哈希表中。需要注意,会不会存在一种情况,当我们在vector中遍历的时候,循环条件是当前结点的状态不为EMPTY,进入了死循环?会的。这是因为我们引入了DELETE的结果,设想表中的所有节点都是DELETE或者EXIST状态,且我们要查找的key不在HashTable中,死循环是必然的情况。
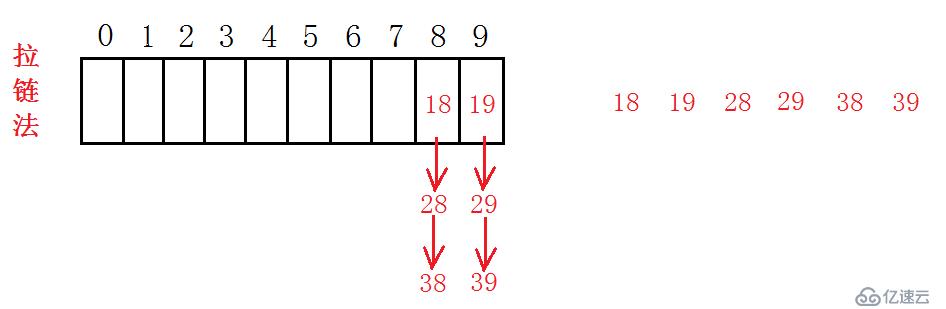
同样一组数据放到拉链法构成的哈希表中,每一个结点不再是只记录key、value值,这里多存放了一个指向next的指针,这样的话vector的每个点上都可以向下追加任意个结点。拉链法似乎更加的有效,载荷因子在这里也显得不是那么重要,但我们依旧需要考虑这个问题。载荷因子虽然在这里的限制比开放地址法更加宽松了些,但是如果我们只是在10个结点下无限制的串加结点,也是会增大查找的时间复杂度。,减轻增容的压力。另外,vector中保存的是 Node* ,这是为了兼容我的向下指针,这样的话,也就不再需要状态标志。初次之外,其他部分和开放地址法相比,思想大致相同。
插入结点:这里我采用的是头插法,原因其实很简单,因为头插的效率比较高,而且只要简单想想,就可以发现,除了结点已经存在以外,其他这里的所有情况可以统一来处理,这就大大简化了代码的冗杂。
查找结点:查找的话,首先定位到哈希地址,然后只需要在对应的位置向下遍历即可。
删除结点:删除结点不建议调用Find函数,如没有找到的话,直接返回,但如果找到的话,还需要再找一遍去删除。所以这里直接去哈希中找相应的key。首先还是需要定位到key所对应的哈希地址,只要不为NULL,就一直向下查找,找不到就返回false,找到了直接 delete 掉就好。
关于整数的哈希算法就到这里,下面给出一张本篇文章的一张简图,便于大家理解HashTable。对于字符串哈希的处理,下一篇会进行介绍。
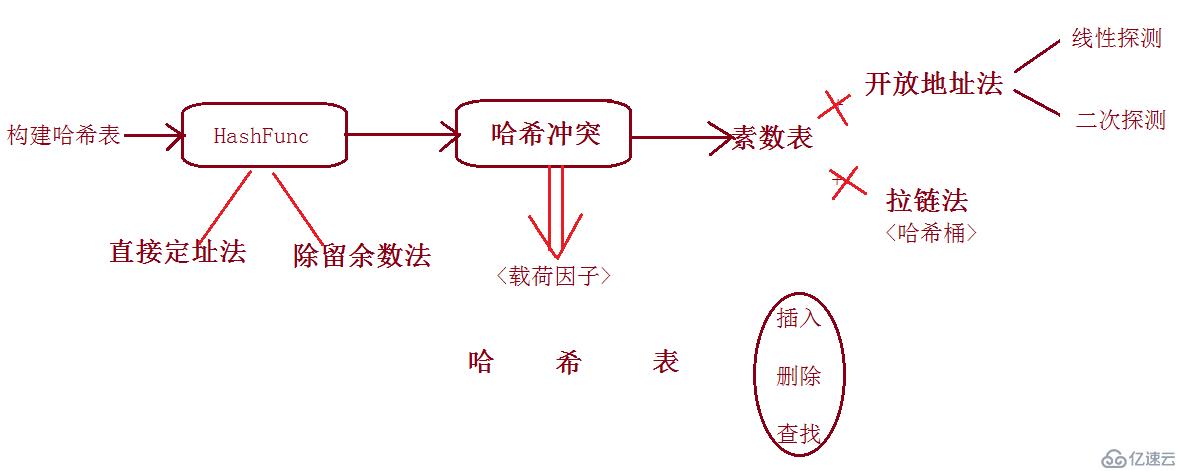
关于哈希算法就分享到这里了,希望以上内容可以对大家有一定的参考价值,可以学以致用。如果喜欢本篇文章,不妨把它分享出去让更多的人看到。